



























この記事でわかること
- LLM(大規模言語モデル)の定義や仕組みを、テキスト生成を担うAI技術の中核として理解できます
- 生成AIやChatGPTとの違いを整理し、それぞれの役割や関係性に基づく特徴を把握できます
- ビジネスでの活用事例や導入時の注意点を踏まえ、実務における活用のポイントを整理できます
目次
LLM(大規模言語モデル)とは何か

LLM(Large Language Model)は、膨大なテキストデータをディープラーニングで学習した自然言語処理モデルです。この学習により、文の前後関係や意味のつながりを理解し、人間に近い自然な言語生成や応答が可能になります。数十億から数千億規模のパラメータを持ち、非常に高精度な言語処理を実現します。
LLMは、特定の業務やドメインに応じたタスクに対応できます。この調整は「ファインチューニング」と呼ばれ、追加データでモデルを再学習させて精度や出力特性を最適化します。
言語モデルの基本概念
言語モデルとは、ある単語や文が現れる確率を予測するモデルのことです。たとえば、「私はご飯を___」といった文の空欄に入る語を予測するようなタスクを通じて、文脈の理解や文章生成を行います。初期の言語モデルはルールベースや統計手法が主流でしたが、現在は「Transformer」と呼ばれる、文章内の単語同士の関係性を同時に処理できるディープラーニング技術が主流となり、文脈を広く考慮した自然な応答が可能になりました。
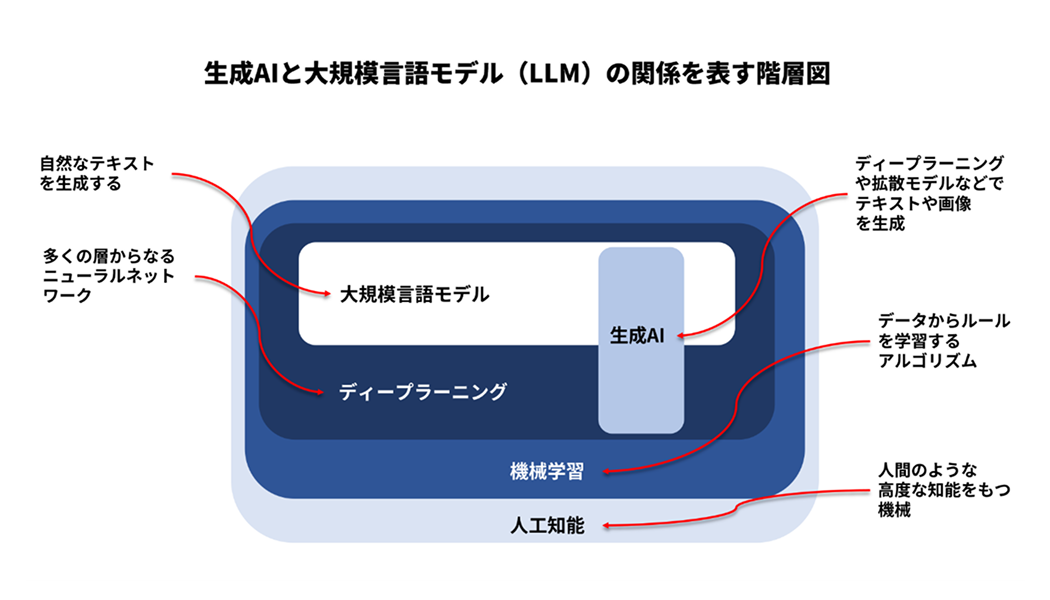
図1: 生成AIと大規模言語モデル(LLM)との関係を表す階層図(『作りながら学ぶ!LLM自作入門』を参考に作成)
「生成AI」との違い
「生成AI」は、テキスト、画像、音声などの多様なコンテンツを自動生成するAIの総称です。これに対して、LLMはテキスト生成に特化した生成AIだといえます。
また、LLMとほかの生成AIとではアルゴリズムも異なり、画像生成には2つの競合するネットワークで学習する「GAN(敵対的生成ネットワーク)」や、ノイズから徐々に画像を生成する「拡散モデル」が使われるのに対して、テキスト生成ではTransformerが用いられるなど、活用するモデルに違いがあります。
「ChatGPT」との違い
ChatGPTは、LLMをベースにした対話型のテキスト生成AIアプリケーションのひとつです。具体的にはOpenAIが開発したGPT(Generative Pre-trained Transformer)というLLMを搭載し、「プロンプト」を介してチャット形式でのやりとりを行います。つまり、ChatGPTはLLMの応用例の一つであり、ほかにもGeminiやGitHub Copilotなど、自然言語やプログラミング言語を処理するLLMが多数開発されています。
LLMが注目されている背景
LLMが注目されている背景には、高精度な言語処理能力と、初心者でも簡単に利用できる手軽さが挙げられます。
従来のAIを超える自然な応答と柔軟性
LLMの大きな特徴は、優れた文脈理解力です。あいまいな質問にも柔軟に対応し、雑談から専門的な問答まで幅広くこなせます。このような柔軟な対応は、従来のAIでは困難でした。事前に定義されたルールに基づく従来型のAIと異なり、LLMはディープラーニングによって膨大なデータから言語パターンを学習し、柔軟な応答を実現しています。
こうしたLLMの特性に着目し、多くの業種で業務効率化や知識支援の手段として関心が高まっています。その応用の汎用性と自然な対話力が、LLMを急速に普及させる要因となっています。
社会や産業に与えるインパクトの大きさ
LLMの登場は、産業界だけでなく一般ユーザーにも大きな衝撃を与えました。たとえば、ライティング、翻訳、プログラミングなどの知的作業においては、自動化や補助が現実のものとなりました。とくにChatGPTの普及をきっかけに、初心者でも高度なAIを扱えるようになりました。
また、教育、医療、ビジネスなど幅広い分野での導入が進んでいます。産業界だけでなく、一般の人々もLLMを検索の代わりに使ったり、時には悩みを相談する「話し相手」として活用したりするようになっています。
LLM導入のご相談ならFPTへ


LLMのテキスト生成の仕組み -5ステップ-
LLMでは、次の5つのステップによりテキストを生成します。
- トークン化
- ベクトル化
- モデルの学習
- 文脈の理解
- デコード
コンピューターは文字そのものを理解できないため、テキストを数値化したあとで、ディープラーニングを実行します。最適な応答が得られると、人間が理解できるように再びテキストに変換しなおします。以下では、GPTが採用するデコーダに焦点を当てたテキスト生成の仕組みを解説します。
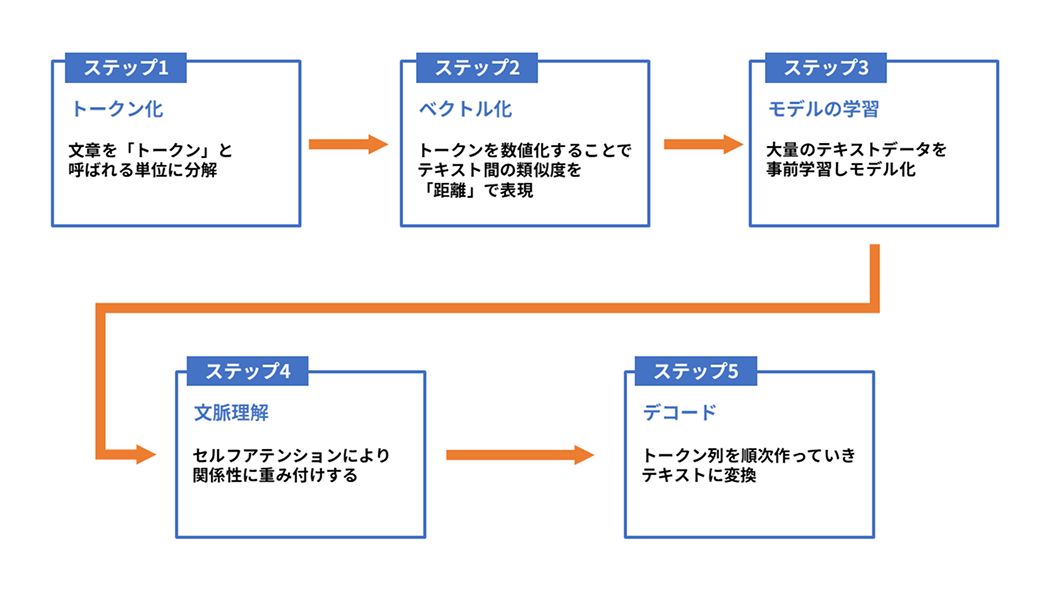
図2: 大規模言語モデル(LLM)でテキストを生成する5つのステップ
トークン化
テキスト生成の最初のステップは、文章を「トークン」と呼ばれる単位に分割する処理です。トークンとは、単語や語幹、文字列の一部などを指します。たとえば「AIを利用する」は「AI」、「を」、「利用」、「する」のように細かく分けられます。LLMはこのトークン列を処理対象とするため、自然言語を機械が理解しやすい形に変換する重要な前処理です。
ベクトル化
トークンを多次元の数値データに変換するのが「ベクトル化」です。この変換により、テキスト間の意味の近さはベクトル空間上での「距離」として表現されます。たとえば「猫」と「犬」は意味的に近いため、ベクトル空間でも互いに近い位置に配置されます。逆に「猫」と「ロケット」のように関連の薄い単語は、遠くに配置されます。
ベクトル化により、意味の違いを1次元の「順序」だけではなく、高次元空間上の位置関係として捉えられます。これは、人間の言語の複雑な意味構造を表すのに不可欠なアプローチだといえます。
モデルの学習
LLMは、数十億から数千億のトークンを含む大規模なテキストデータをもとに学習されます。ここでの学習は「事前学習(pre-training)」と呼ばれ、Transformerアーキテクチャに基づいたディープラーニングにより、言語のパターンや文脈の理解、単語同士の関係性などがモデル内部に取り込まれていきます。このプロセスによって、LLMは多様なタスクに対応可能な汎用的な言語知識を獲得します。
文脈理解
ベクトル化されたトークン列は、セルフアテンション(自己注意機構)と呼ばれる仕組みによって処理されます。セルフアテンションとは、各トークンが文章内の他のすべてのトークンを同時に参照し、重要な関係性に高い重みを置くことで文脈を理解する手法を指します。
たとえば「彼は昨日の会議で重要な発言をした」という文では、「彼」と「発言」の関係性が強く結びついていると判断され、そのつながりが重みに反映されます。この重み付けによって、次に来るトークンの確率分布が計算されます。セルフアテンションによる重み付けこそが、次の単語を的確に予測するための土台となります。
デコード
文脈理解によって得られた情報をもとに、モデルは次に続くトークンを順番に選び出します。これを繰り返すことで、トークン列が形成されます。デコードでは、このトークン列を再び人間が読める自然言語の文章へと変換します。
たとえば、「私はご飯を___」という入力から「食べた」というトークンが選ばれると、それが文章に追加され、次の予測が行われます。この生成と変換の繰り返しによって、意味の通った文章が一文ずつ完成していきます。
LLMの2つのモデル

ChatGPTの登場以来、さまざまなLLMが登場しました。中には、小規模・中規模言語モデルにファインチューニングしやすいオープンソース型のLLMも増えています。そこで、オープンソース型と独立開発型のLLMの概要や具体的なアプリケーションについて説明します。
オープンソース型モデル
オープンソース型のLLMは、ソースコードが公開され、ライセンス条件に従って利用・改良できるモデルです。代表例としては、MetaのLLaMAシリーズがあります。LLaMA 2は高い性能と安定性を持ち、学術研究や商用利用にも対応可能です。GoogleのGemmaも軽量モデルとして知られており、ライセンス条件も柔軟です。LLaMA系と互換性があり、ローカル環境での高速な推論や組み込みアプリでの利用も視野に入ります。国内でも、楽天のRakutenAIシリーズがあり、日本語データで追加学習されており、国内用途に向いています。
これらのモデルは、多くが軽量設計で、自前のGPUサーバーやローカル環境でも動作可能です。また、自社のデータでファインチューニングを行えば、特定業務や分野に特化した高精度な応答が可能になります。
独自開発型モデル
独自開発型モデルとは、企業が独自に設計・学習した大規模言語モデルで、内部構造や学習データ、学習手法などが非公開とされているタイプのLLMです。これらのモデルは、API経由での提供が中心で、一般的に自社インフラに直接導入することはできません。
代表例のひとつであるChatGPTは、自然な対話能力と高い応答精度、豊富なツールとの連携が特長です。また、GoogleのGeminiシリーズは、検索エンジンやGmail、Googleドキュメントなど、Googleのほかのサービスとの連携が可能です。さらに、Anthropic社のClaudeシリーズは、安全性と倫理性を重視したLLMとして開発されており、「ハルシネーション(虚偽の生成)」を抑えた設計が特徴です。
これらのモデルの多くは商用利用に対応しているため、企業にとっては、信頼性の高いLLMとして活用しやすいといえます。
LLMのビジネス活用事例
LLMのビジネス活用は主に、テキストに関する多くの業務を網羅していることだといえます。そこで、LLMのビジネス活用の代表例を2つ紹介します。
チャットボットによる業務効率化と顧客対応
LLMを活用したチャットボットは、企業のカスタマーサポートや社内ヘルプデスクなどに広く導入され始めています。従来のルールベースのFAQ応答に比べて、より自然な対話が可能で、あいまいな質問にも柔軟に対応できるのが特長です。24時間対応が可能になることで、ユーザー満足度を高めながら、オペレーターの負担を大幅に軽減できます。また、対応履歴の要約や社内ナレッジとの連携により、情報管理の効率化にも貢献しています。
コンテンツ制作やマーケティング支援
LLMは、文章作成の補助ツールとしても有効です。ブログ記事や製品紹介文、SNS投稿の草稿作成など、コンテンツ制作の効率を高めながら、表現の多様性を広げることができます。また、顧客属性や検索キーワードに応じた広告コピーの生成、メール文面の自動作成といった活用も進んでいます。チャットボットと連動して、見込み客への対応や情報提供を行うことで、マーケティングの一環としての活用も広がっています。
高性能GPUクラウドと統合型AI開発プラットフォーム、さらに即戦力となる生成AIアプリケーション群により、企業のLLM導入を加速し、業務効率と競争力を高めます
LLMのビジネス導入時の注意点と対応策
LLMの業務活用は大きな効果が期待できる一方、適切な運用のためには以下の点に注意が必要です。
- 機密情報の漏洩
- 誤情報の出力リスク
- 目的なく利用することによる、業務量の増加
以下では、これらの3点について詳しく見ていきます。
機密情報の取り扱いに注意する
LLMをクラウド経由で利用する場合、入力内容が外部サーバーに送信されることがあるため、機密情報や個人データの取り扱いには慎重な配慮が必要です。重要な業務にLLMを活用する際は、社内向けにオンプレミス版を導入する、あるいはChatGPTのようにサーバーに入力データを送信しないようにする「オプトアウト」を選択するなどの対策が求められます。情報管理体制の見直しも併せて行うとよいでしょう。
誤情報や偏りへの対策
LLMは学習データに含まれる誤情報や偏見を反映してしまう可能性があります。LLMの出力は必ず人間がチェックする体制が重要です。これにより、誤情報の拡散を防ぎ、組織の価値観や品質基準を保つことができます。とくに、医療・法律・金融などの分野では信頼性の担保が不可欠です。
導入目的と活用範囲の明確化
LLMは多用途に利用できますが、明確な目的や評価指標がないまま導入すると、期待外れに終わるだけでなく、かえって業務量が増える危険があります。たとえば、目的が曖昧なまま社内で試験的に利用を始めると、生成結果の確認や修正に余計な時間がかかり、人的リソースが圧迫されることがあります。また、ファインチューニング可能なモデルを導入したにもかかわらず、利用目的が不明確だったために出力精度が安定しないままLLMを使用してしまうことがあります。
まずは特定の業務課題に絞って導入し、効果を検証しながら段階的に範囲を広げるアプローチが効果的です。目的と活用範囲を明確にすることで、導入コストや運用負荷を抑えつつ、現場への定着と成果の最大化を図ることができます。
LLMの今後の展望

今後のLLMは、単なる精度向上や軽量化にとどまらず、より人間的な言語理解へと進化していくでしょう。たとえば、ユーザーの意図や感情の理解、長文文脈の保持といった対話の深化に加えて、画像・音声・表など複数の情報を統合的に扱う「マルチモーダル処理」が現実のものとなりつつあります。
また、LLMにタスク実行や判断機能を持たせたAIエージェントの開発も進み、人間に近い知的支援の実現が期待されています。教育、行政、医療、産業などあらゆる分野において、その影響はますます拡大していくでしょう。
LLM導入のご相談ならFPTへ
FPTのLLM活用
FPTは自社開発のAIエージェントシステム「PrivateGPT」を活用し、生産性向上と強化されたセキュリティによる情報保護を実現しています。
コミュニケーション部門では、ニュース制作ソリューション「AI4News」に「PrivateGPT」を導入し、静止画からの動画作成や白黒写真のカラー化、記事・タイトルの自動生成など、多様な機能を可能にしました。これにより、制作コストと時間を大幅に削減し、迅速かつ高品質なコンテンツ制作を実現し、ニュース現場の効率化とイノベーションに大きく貢献しています。
まとめ
LLMは、自然な文章生成や高度な文脈理解を可能にする革新的な技術であり、生成AIの中心的存在として、ビジネスや社会に大きな影響を与えつつあります。すでにビジネスの現場では、従来の業務をLLMに任せることで、効率化と人材の有効活用を実現しています。
マルチモーダル化やAIエージェント化といった進化により、LLMの可能性はさらに広がっており、効果的な活用スキルがますます重要になっています。
生成AIについてもっと知るなら
- ファインチューニングとは?目的やRAGとの違い、やり方をわかりやすく解説
- SLM(小規模言語モデル)とは?仕組みやLLMとの違い、活用事例を解説
- マルチモーダルAIとは?仕組みや業界別活用事例を紹介
- 今注目のAIエージェントとは?他のAI技術との違いやビジネス活用事例を解説
- 生成AIの主なツール13選 - 従来のAIとの違いや効果的な使い方を解説
この記事の監修者・著者:FPTコンテンツ制作チーム
FPTコンテンツ制作チームは、ITソリューションやデジタル技術に関する情報を発信しています。業界動向や技術トピックについて、記事の制作を行っています。
監修者・著者の詳しい情報はこちら →
関連リンク
- AI(人工知能)サービス
- FPTがAIプラットフォーム「FleziPT」を発表し、グローバルな企業変革を加速
- FPTは、企業のAIエージェント活用を支援する「FPT AIXサービス」の提供を開始
- FPT、SBIホールディングス、住友商事によるAIソリューションサービス提供に向けた戦略的提携に関するお知らせ
- FPT、包括的なAIインフラ、プラットフォーム、アプリケーションを提供する子会社を日本に設立
関連ブログ:コラム
- クラウドとは?意味や具体のサービス例を分かりやすく解説
- CRMとは?機能や導入メリット、活用方法と導入事例まで解説
- ランサムウェアとは?被害事例や感染経路、被害防止対策を解説
- ICT(情報通信技術)とは何? IT、IoTとの違いや教育・介護・医療現場での活用例を徹底解説
- OutSystems(アウトシステムズ)とは?メリット・デメリットや将来性、導入方法まで解説









