



























目次
ファインチューニングとは既存モデルを微調整すること

ファインチューニング(Fine-tuning)とは、大量のテキストデータであらかじめ学習済みのAIモデルに対して、特定のタスクや業務領域に関する新しいデータを追加で学習させ、モデルのパラメータ(内部の数値設定)を調整する手法です。「追加学習」とも呼ばれます。ゼロからAIを開発するよりも少ないコストと時間で、特定業務に特化した高精度なAIを作れる点が最大の特徴です。たとえば、汎用的なチャットAIを自社の製品問い合わせ専用に育て直すイメージです。
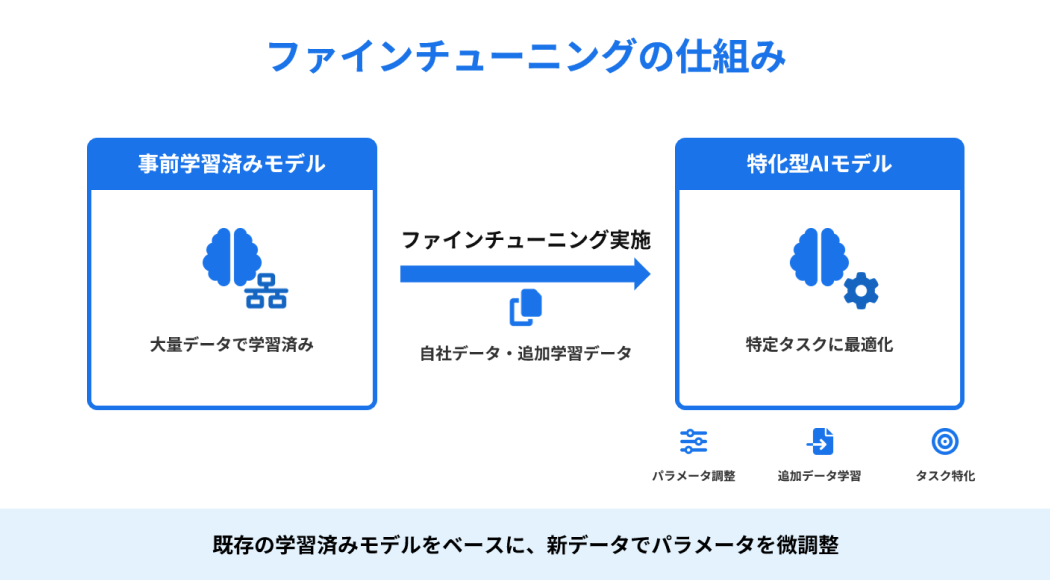
ファインチューニングの仕組み
ファインチューニングでは、ニューラルネットワーク(AIの神経回路のようなもの)内部のパラメータを、新しいデータに合わせて再調整します。具体的には、事前学習済みモデルに自社データを読み込ませ、「学習率」「エポック数」などのハイパーパラメータ(学習の設定値)を指定しながらトレーニングを実行します。モデルは既存の知識を保ちながら、新しい知識やトーン・表現スタイルを追加・調整するように学習します。これにより、特定業種や社内用語にも自然に対応できるモデルへと進化させることができます。
【関連記事】
⇒LLMとは?生成AIやChatGPTとの違い、活用事例をわかりやすく解説
ファインチューニングとRAG(検索拡張生成)の違い
ファインチューニングと混同されやすい技術に「RAG(Retrieval-Augmented Generation:検索拡張生成)」があります。RAGとは、AIが回答を生成する際に外部のデータベースやドキュメントを検索して参照する手法です。どちらも「AIをより賢くする」アプローチですが、仕組みや用途が異なります。
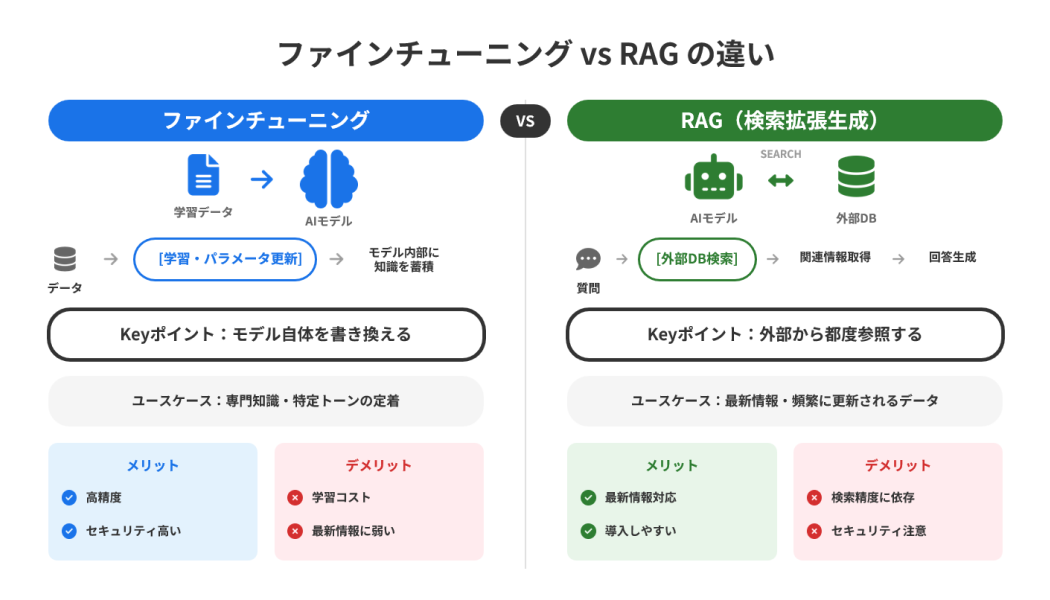
ファインチューニングは「モデル自体に知識を覚えさせる」イメージ、RAGは「必要なときに外から参照する」イメージです。最新情報へのリアルタイム対応が重要な場合はRAG、自社特有の言い回しや専門知識をモデルに定着させたい場合はファインチューニングが適しています。両者を組み合わせて活用するケースも増えています。
AIモデルのファインチューニングのご相談ならFPTへ


ファインチューニングと転移学習(Transfer Learning)の違い
転移学習(Transfer Learning)とは、あるタスク向けに学習済みのモデルを別のタスクに応用する手法で、ファインチューニングはその転移学習の一種と位置づけられます。ただし、実際には両者の使い方には明確な違いがあります。

転移学習はより広い概念で、ファインチューニングはその中の「パラメータを積極的に更新する手法」に相当します。似た言葉ですが、どの範囲まで更新するかという観点で使い分けられています。
ファインチューニングを実施する目的・メリット
ファインチューニングを導入する主なメリットは3つです。
- 特定タスクへの精度向上
- 開発コスト&時間の削減
- 自社固有のトーンや機密情報の反映
1. 特定タスクへの精度向上
ファインチューニングの最大のメリットは、特定の業務や業界に特化した高い精度を実現できることです。汎用的な大規模言語モデルは幅広い知識を持つ一方、医療・法律・金融などの専門領域では回答の精度にばらつきが生じることがあります。自社ドメインのデータでファインチューニングを行うことで、専門用語の正確な使用や業界特有の文脈に沿った回答が可能になり、実業務での信頼性が大きく向上します。
2. 開発コスト&時間の削減
ファインチューニングは、ゼロからAIモデルを開発する場合と比較して、コストと時間を大幅に抑えられます。大規模モデルの事前学習には膨大な計算リソースと時間が必要ですが、ファインチューニングでは既存の学習済みモデルをベースに、追加データだけを学習させるためです。スタートラインが高い分、自社ユースケースへの適応も速く、AIプロジェクトのリードタイムを短縮できます。
3. 自社固有のトーンや機密情報の反映
ファインチューニングでは、自社のブランドトーンや業務上の言い回し、外部公開していない社内知識をモデルに直接学習させることができます。たとえば「社内Q&Aデータ」や「カスタマーサポートの応答履歴」を学習させることで、自社らしい言葉遣いで回答するAIを実現できます。自社環境でファインチューニングを行う場合、機密情報を外部に送信せずにモデル内部に組み込める点も、セキュリティ面で大きなメリットです。
ファインチューニングを実施する際の注意点・デメリット
ファインチューニングには多くのメリットがある一方、導入時には「過学習(オーバーフィッティング)のリスク」と「高い計算コストとリソース要件」を考慮する必要があります。
1. 過学習(オーバーフィッティング)のリスク
過学習とは、モデルが学習データに過度に特化してしまい、実際の業務では使いにくくなる現象です。たとえばデータ量が少ない場合、モデルは「パターンを学ぶ」のではなく「データを丸暗記」してしまいます。その結果、学習データには完璧に回答できても、少し違う質問には対応できなくなります。防止策としては、学習データを十分に用意すること、学習率(パラメータの更新幅)を小さく設定すること、正則化(モデルの複雑化を抑える技術)を活用することが有効です。データの品質と多様性を高めることも、過学習防止に大きく貢献します。
2. 高い計算コストとリソース要件
ファインチューニングでは、モデルのパラメータを実際に更新するため、高性能なGPU(グラフィックス処理ユニット)と大容量のメモリが必要です。特に数十億〜数百億パラメータを持つ大規模モデルを対象とする場合、自前のサーバーで行うにはコストが高くなります。コスト削減のアプローチとしては、一部の層だけを更新する「部分的ファインチューニング」や、元のパラメータを固定したまま、少数の追加パラメータだけで効率的に学習できる「LoRA(Low-Rank Adaptation)」などの手法が注目されています。また、クラウドサービスのマネージドAPIを利用することで、インフラ管理の手間を省くことも可能です。
ファインチューニングを行う FPT AI Studio を含む、FPT AI Factoryの概要についてはこちらで紹介しています
ファインチューニングのやり方

ファインチューニングは大きく4つのステップで進めます。使用するモデルやクラウドサービスによって細部は異なりますが、基本的な流れは共通しています。初めて取り組む場合は、OpenAIやAWSなどのマネージドサービスを利用すると、環境構築の手間を大幅に省けます。
1. データとベースモデルの準備
まず、ファインチューニングに使う学習データと、ベースとなるモデルを準備します。データはJSONL形式(1行に1つのデータが入るテキスト形式)などの指定フォーマットで用意するのが一般的です。品質の低いデータや誤字脱字が多いデータは学習結果に悪影響を与えるため、事前のクリーニングが重要です。ベースモデルは、GPT-4oやClaude、オープンソースのLlamaなど、用途とコストを踏まえて選択します。
2. データのアップロードと設定
準備したデータをAIプラットフォームのAPIやダッシュボードにアップロードします。このとき、学習データ(training data)と検証データ(validation data)を分けて用意するのが理想的です。検証データは学習の途中経過を評価するために使います。あわせて、エポック数(データを何周学習させるか)や学習率などのハイパーパラメータ(学習の設定値)を指定します。
3. 学習の実行とモニタリング
設定が完了したら、学習ジョブを開始します。学習は数分〜数時間程度かかる場合があります。多くのプラットフォームでは、学習の進捗状況(損失値の推移など)をダッシュボードやAPIで確認できます。損失値(ロス)が下がらなかったり、急に上昇したりする場合は、ハイパーパラメータや学習データを見直すサインです。
4. 評価と本番適用
学習が完了したモデルに対して、テスト用の質問や実業務に近いシナリオで回答品質を確認します。期待する品質を満たしていない場合は、学習データの追加・改善やハイパーパラメータの調整を行い、再度学習を実行します。評価・調整を繰り返して品質を高めたうえで、本番環境への適用を進めましょう。
ファインチューニングの実施が推奨されるデータの例
ファインチューニングにどのようなデータを使えばよいのか、代表的な3種類の例を紹介します。
社内固有のデータ(業務マニュアル・顧客対応履歴など)
業務マニュアル、社内FAQドキュメント、カスタマーサポートのやり取り履歴、社内報などのデータは、ファインチューニングに最も適したデータのひとつです。これらは外部から入手できない自社固有の情報であり、学習させることでAIが社内用語や独自のプロセスを正確に理解・活用できるようになります。社員の問い合わせ対応を自動化したり、新人教育向けのQ&Aを構築したりする際に特に効果を発揮します。ただし、個人情報や機密情報が含まれる場合は、事前の匿名化や適切なアクセス管理が不可欠です。
専門性の高いドメインデータ(医療・法律・金融など)
医療診断ガイドライン、法律判例データ、金融規制文書など、一般公開データに少ない高度な専門知識を含むデータも、ファインチューニングに適しています。汎用モデルでは回答精度が不安定になりがちな専門領域でも、ドメイン特化のデータで学習させることで、業界水準の専門的な回答を安定して生成できるようになります。医師向けの診断支援AIや、弁護士向けの契約書レビューAIなど、高い専門性が求められる用途に向いています。データは信頼性の高いソース(学会発行のガイドラインや公的機関の文書など)を優先して使用しましょう。
学習済みモデルが知らない新しい情報
大規模言語モデルの学習データには「カットオフ日」(データ収集の締め切り日)があり、それ以降に公開された情報はモデルが知りません。自社の新製品情報、直近の組織変更、最新の業界動向など、リリース後に生まれたデータをファインチューニングに活用することで、モデルを最新状態に保てます。たとえば毎年改訂される規制文書や製品カタログのデータを定期的に学習させることで、常に正確な情報を提供できるAIを維持できます。データは定期的に更新・バージョン管理し、古い情報との混在に注意することが重要です。
AIモデルのファインチューニングのご相談ならFPTへ
まとめ
本記事では、ファインチューニングの定義・仕組みから、RAG・転移学習との違い、メリット・注意点、具体的なやり方、推奨データの例まで解説しました。ファインチューニングは、既存のAIモデルを自社業務に最適化するうえで強力な手段です。過学習や計算コストといった課題を把握し、適切なデータと手順で取り組むことで、業務効率化や専門的なAI活用を実現できます。導入を検討する際は、まず目的に合ったベースモデルとデータの整備から始めてみましょう。
この記事の監修者・著者:FPTコンテンツ制作チーム
FPTコンテンツ制作チームは、ITソリューションやデジタル技術に関する情報を発信しています。業界動向や技術トピックについて、記事の制作を行っています。
監修者・著者の詳しい情報はこちら →
関連リンク
- AIサービス
- FleziPT
- FPTスマートクラウドジャパン
- FPTはServiceNowのPremierパートナーに昇格、企業のAIトランスフォーメーションを加速
- FPTと三島光産は、AIを活用した次世代製造基盤構築の協業に合意
関連ブログ:コラム
- ODC(ラボ型開発)とは?メリットやデメリット、導入手順をわかりやすく解説
- 物流DXとは何?業界の現状や課題、取り組みの具体例を徹底解説
- 地政学リスクとは?海外進出企業への影響や必要なリスクマネジメントを解説
- 2025年の崖とは何?DX化が進まない原因や課題、進める方法を解説
- リバースエンジニアリングの手法や目的、活用のメリットやリスクを徹底解説









